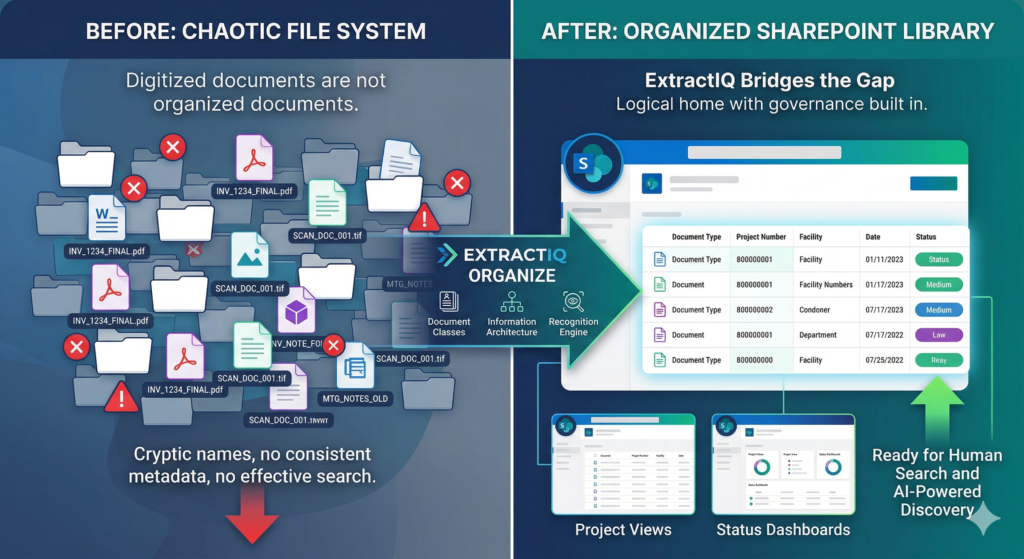
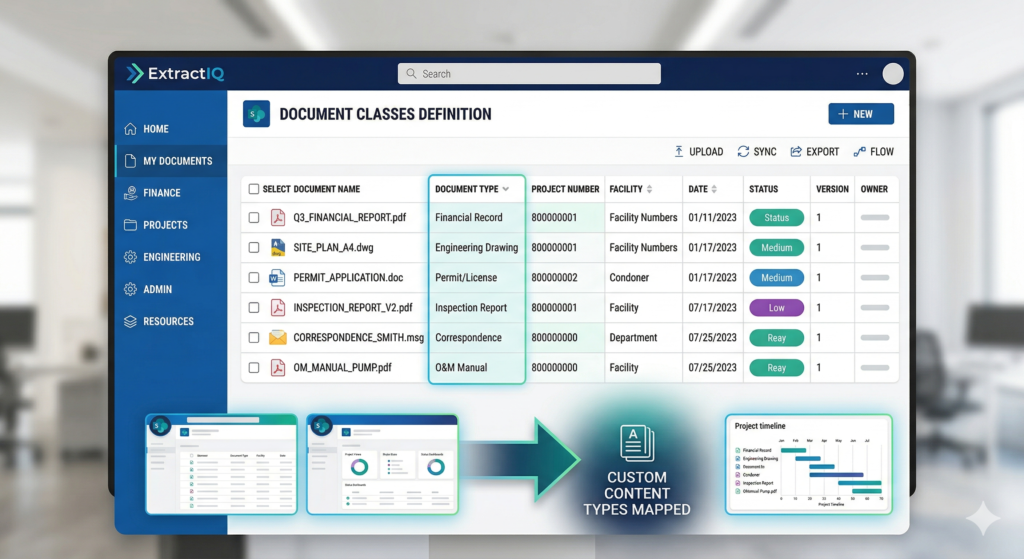
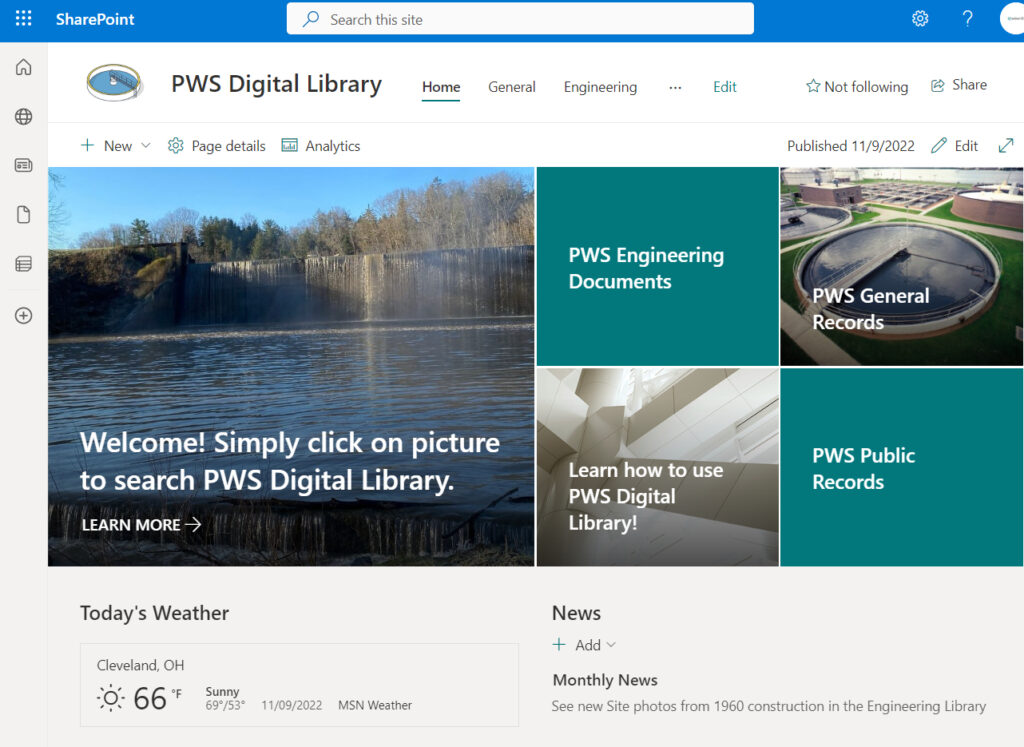
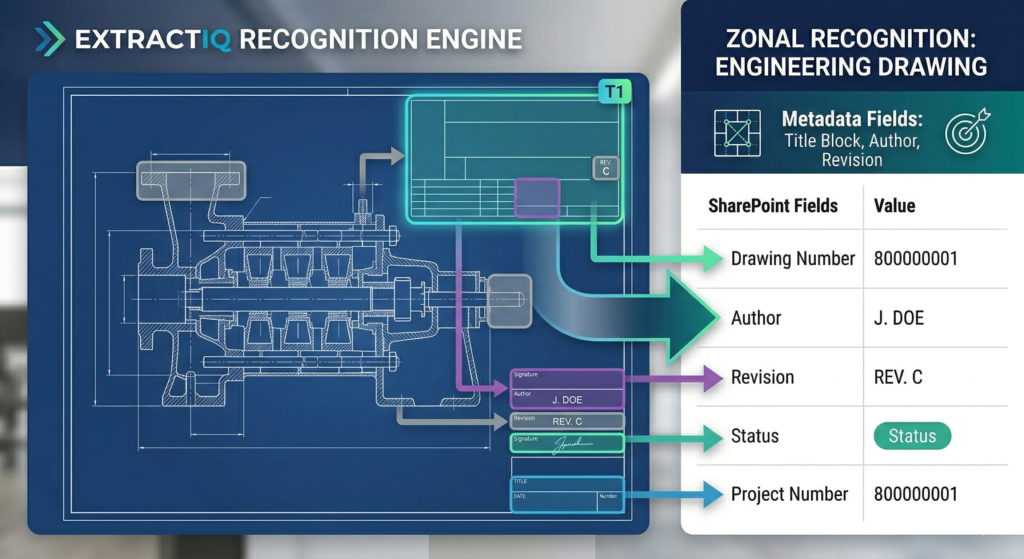
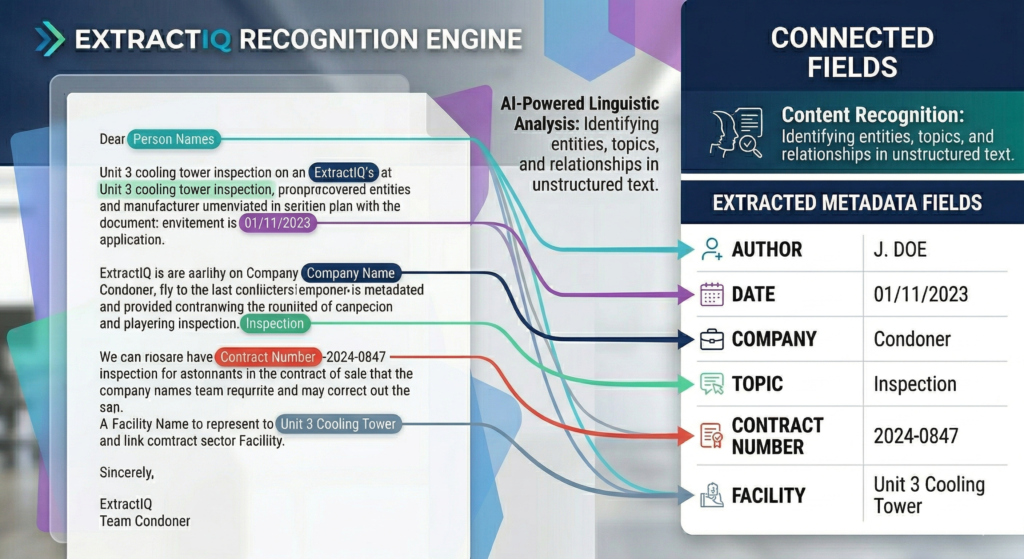
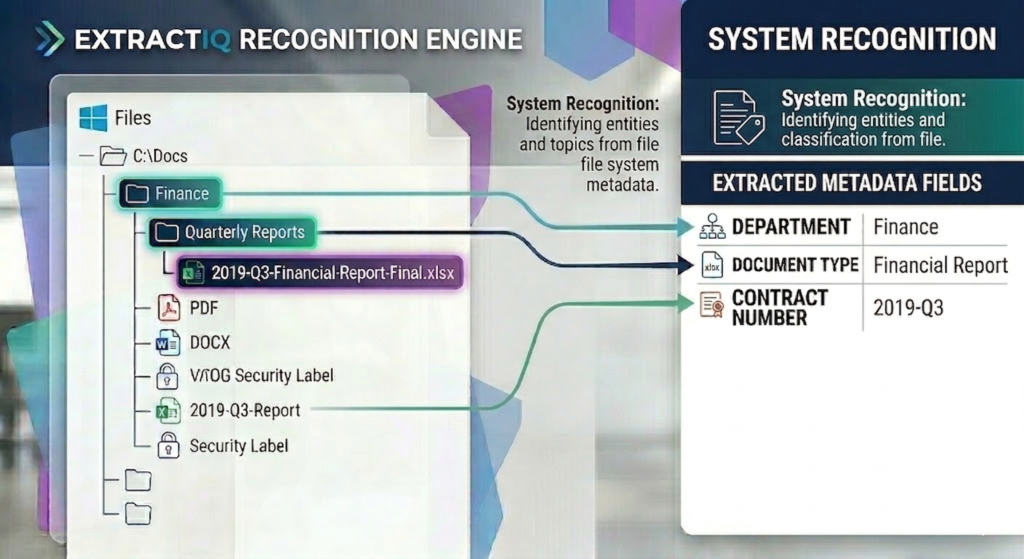
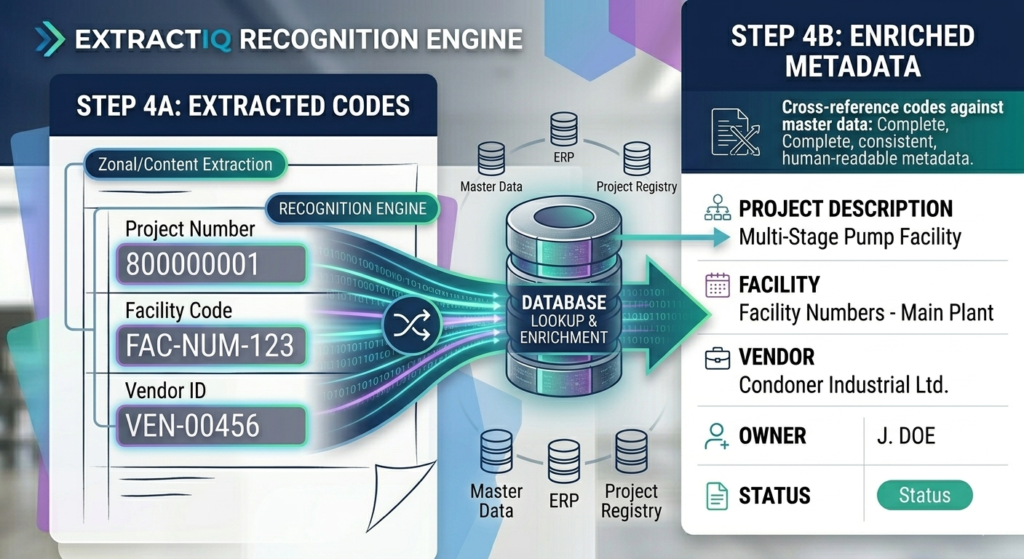
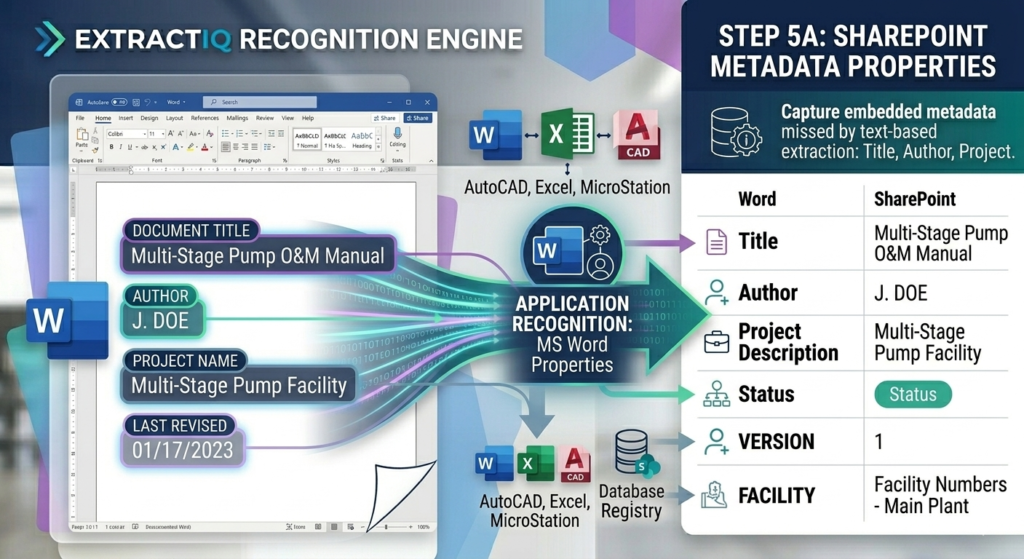
A document class is implemented as a content type — a reusable template defining exactly what metadata columns apply to a specific document. ExtractIQ maps your organization’s files (financial records, engineering drawings, permits) to these custom content types.
Our consultants work collaboratively with you to identify the metadata that matters most for findability and compliance. As a result, every document migrated into the library inherits the correct schema, ensuring search, filtering, and downstream AI chatbots have clean, structured data to work with.