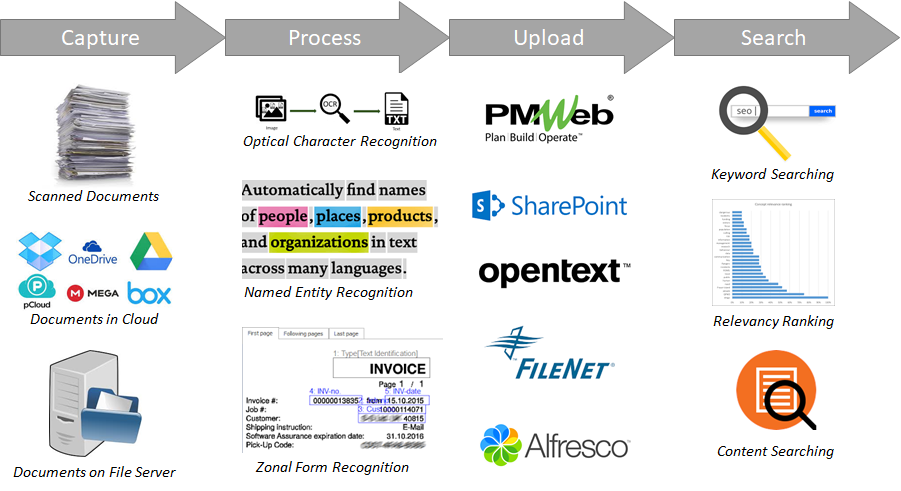
ExtractIQ products can be used standalone or coupled together to form a specific customer solution. As an example, ExtractIQ Upload can be used standalone to automate uploading documents into a Document Management System or can be used in conjunction with ExtractIQ Process to perform Natural Language Processing to automatically extract the metadata required to upload the documents.
